1. 만년달력 그리기
풀이1) IW로 주차를 계산하기
SELECT
-- 일요일이라면 날짜(DD)를 찍고 나머지는 NULL로 찍겠다.
NVL( MIN( DECODE(TO_CHAR(dates, 'D'), 1, TO_CHAR(dates, 'DD') ) ), ' ') 일
, NVL(MIN( DECODE(TO_CHAR(dates, 'D'), 2, TO_CHAR(dates, 'DD') ) ), ' ') 월
, NVL(MIN( DECODE(TO_CHAR(dates, 'D'), 3, TO_CHAR(dates, 'DD') ) ), ' ') 화
, NVL(MIN( DECODE(TO_CHAR(dates, 'D'), 4, TO_CHAR(dates, 'DD') ) ), ' ') 수
, NVL(MIN( DECODE(TO_CHAR(dates, 'D'), 5, TO_CHAR(dates, 'DD') ) ), ' ') 목
, NVL(MIN( DECODE(TO_CHAR(dates, 'D'), 6, TO_CHAR(dates, 'DD') ) ), ' ') 금
, NVL(MIN( DECODE(TO_CHAR(dates, 'D'), 7, TO_CHAR(dates, 'DD') ) ), ' ') 토
FROM(
SELECT TO_DATE(:yyyymm, 'YYYYMM') + LEVEL - 1 dates
FROM dual
CONNECT BY LEVEL <= EXTRACT(DAY FROM LAST_DAY(TO_DATE(:yyyymm, 'YYYYMM')))
) t
GROUP BY CASE
-- IW 값이 50주가 넘으면서 일요일(1)이라면 1을 주고, 일요일(1)이 아니라면 0을 주겠다.
WHEN TO_CHAR(dates, 'MM') = 1 AND TO_CHAR(dates, 'D') = 1 AND TO_CHAR(dates, 'IW') > 50 THEN 1
WHEN TO_CHAR(dates, 'MM') = 1 AND TO_CHAR(dates, 'D') != 1 AND TO_CHAR(dates, 'IW') > 50 THEN 0
WHEN TO_CHAR(dates, 'D') = 1 THEN TO_CHAR(dates, 'IW') + 1
ELSE TO_NUMBER(TO_CHAR(dates, 'IW'))
END
ORDER BY CASE
WHEN TO_CHAR(dates, 'MM') = 1 AND TO_CHAR(dates, 'D') = 1 AND TO_CHAR(dates, 'IW') > 50 THEN 1
WHEN TO_CHAR(dates, 'MM') = 1 AND TO_CHAR(dates, 'D') != 1 AND TO_CHAR(dates, 'IW') > 50 THEN 0
WHEN TO_CHAR(dates, 'D') = 1 THEN TO_CHAR(dates, 'IW') + 1
ELSE TO_NUMBER(TO_CHAR(dates, 'IW'))
END
;
풀이2) D로 주차를 계산하기
SELECT
-- 일요일이라면 날짜(DD)를 찍고 나머지는 NULL로 찍겠다.
NVL( MIN( DECODE(TO_CHAR(dates, 'D'), 1, TO_CHAR(dates, 'DD') ) ), ' ') 일
, NVL(MIN( DECODE(TO_CHAR(dates, 'D'), 2, TO_CHAR(dates, 'DD') ) ), ' ') 월
, NVL(MIN( DECODE(TO_CHAR(dates, 'D'), 3, TO_CHAR(dates, 'DD') ) ), ' ') 화
, NVL(MIN( DECODE(TO_CHAR(dates, 'D'), 4, TO_CHAR(dates, 'DD') ) ), ' ') 수
, NVL(MIN( DECODE(TO_CHAR(dates, 'D'), 5, TO_CHAR(dates, 'DD') ) ), ' ') 목
, NVL(MIN( DECODE(TO_CHAR(dates, 'D'), 6, TO_CHAR(dates, 'DD') ) ), ' ') 금
, NVL(MIN( DECODE(TO_CHAR(dates, 'D'), 7, TO_CHAR(dates, 'DD') ) ), ' ') 토
FROM(
SELECT TO_DATE(:yyyymm, 'YYYYMM') + LEVEL - 1 dates
FROM dual
CONNECT BY LEVEL <= EXTRACT(DAY FROM LAST_DAY(TO_DATE(:yyyymm, 'YYYYMM')))
) t
GROUP BY CASE
WHEN TO_CHAR( dates, 'D' ) < TO_CHAR( TO_DATE( :yyyymm,'YYYYMM' ), 'D' ) THEN TO_CHAR( dates, 'W' ) + 1
ELSE TO_NUMBER( TO_CHAR( dates, 'W' ) )
END
ORDER BY CASE
WHEN TO_CHAR( dates, 'D' ) < TO_CHAR( TO_DATE( :yyyymm,'YYYYMM' ), 'D' ) THEN TO_CHAR( dates, 'W' ) + 1
ELSE TO_NUMBER( TO_CHAR( dates, 'W' ) )
END;
<결과물>

2. LEVEL 의사컬럼과 계층적 질의
- [참조] 테이블에서 행(row)의 LEVEL를 가리키는 일련번호 순서
1) [LEVEL과 관련된 3가지 함수]
ㄱ. CONNECT_BY_ISLEAF
- 더 이상 LEAF 데이터가 없으면 1, 있으면 0을 반환 (자식 데이터 유무에 따라 있으면 0, 없으면 1)
ㄴ. CONNECT_BY_ISCYCLE
- root 데이터이면 1, 아니면 0을 반환
ㄷ. CONNECT_BY_ROOT
- 각 데이터의 root값과 LEVEL 값을 반환
2) [계층적 질의(hierarchical query)]
ㄱ. 계층적 질의문은 조인문이나 뷰에서는 사용할 수 없으며,
ㄴ. CONNECT BY 절에서는 서브쿼리 절을 포함할 수 없다.
3) 【형식】
SELECT [LEVEL] {*,컬럼명 [alias],...}
FROM 테이블명
WHERE 조건
START WITH 조건
CONNECT BY [PRIOR 컬럼1명 비교연산자 컬럼2명]
또는
[컬럼1명 비교연산자 PRIOR 컬럼2명]
- START WITH 절 : 계층적인 출력 형식을 표현하기 위한 최상위 행
- CONNECT BY 절 : 계층관계의 데이터를 지정하는 컬럼
- PRIOR 연산자 : CONNECT BY는 PRIOR 연산자와 함께 사용하여 부모 행을 확인할 수 있다.
PRIOR 연산자의 위치에 따라 top-down 방식인지 bottom up 방식인지를 결정한다.
PRIOR 자식키 = 부모키(top-down 방식)
- WHERE 절 : JOIN을 포함하고 있을 경우 CONNECT BY 절을 처리하기 전에 JOIN 조건부를 적용하여 처리하고, JOIN을 포함하고 있지 않을 경우 CONNECT BY 절을 처리한 후에 WHERE 절의 조건을 처리한다.
- LEVEL 계층적 질의문에서 검색된 결과에 대해 계층별로 레벨 번호 표시, 루트 노드는 1, 하위 레벨로 갈 수록 1씩 증가
4) 계층적 질의는 어디에 사용하는가?
> 답글을 달 수 있는 게시판 즉, 답변형 게시판을 구현할 때 계층적 질의를 사용하면 된다.
하지만 사용하지 않는 이유는 계층적 질의는 DBMS 중 오라클에서만 사용이 가능하기 때문에 잘 사용하지 않는다. 호환이 되는 시스템으로 구현하는 것이 중요!
계층적 질의 예시)
SELECT empno, ename, mgr, LEVEL
FROM emp
-- START WITH emp = 7839 -- 이렇게 king의 사원번호를 넣어도 되고,
START WITH mgr IS NULL -- 사수가 없는 사람 즉, mgr이 null인 사람
CONNECT BY PRIOR empno = mgr; -- 계층 관계를 나타내는 컬럼을 연결해줘야함
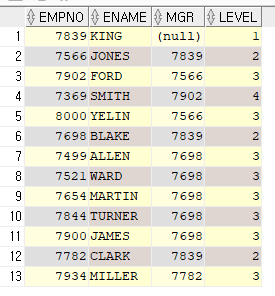
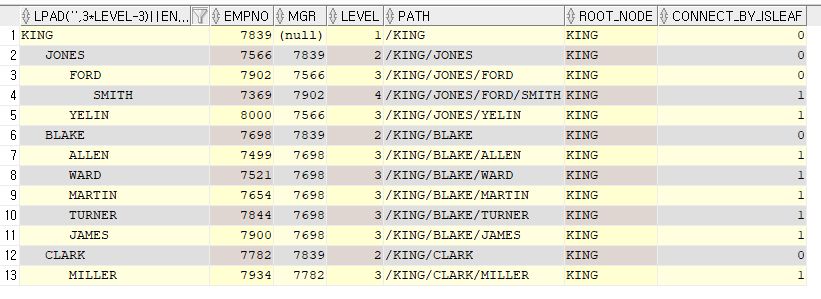
> LPAD(' ', 3*LEVEL-3) || ename 쿼리를 추가하면 아래의 결과처럼 계층적 구조를 볼 수 있다.
SELECT LPAD(' ', 3*LEVEL-3) || ename
, empno, mgr, LEVEL
, SYS_CONNECT_BY_PATH(ename, '/') path
, CONNECT_BY_ROOT ename ROOT_NODE
, CONNECT_BY_ISLEAF
FROM emp
START WITH mgr IS NULL
CONNECT BY PRIOR empno = mgr;
계층적 질의를 더 확인하기 위해서 아래와 같은 테이블 생성 및 데이터를 추가하자
<테이블 생성>
create table tbl_level(
deptno number(3) not null primary key,
dname varchar2(30) not null,
college number(3),
loc varchar2(10)
);
<데이터 추가>
insert into tbl_level ( deptno, dname, college, loc ) values ( 10,'공과대학', null , null);
insert into tbl_level ( deptno, dname, college, loc ) values ( 100,'정보미디어학부',10, null );
insert into tbl_level ( deptno, dname, college, loc ) values ( 101,'컴퓨터공학과',100,'1호관');
insert into tbl_level ( deptno, dname, college, loc ) values ( 102,'멀티미디어학과',100,'2호관');
insert into tbl_level ( deptno, dname, college, loc ) values ( 200,'메카트로닉스학부', 10,null);
insert into tbl_level ( deptno, dname, college, loc ) values ( 201,'전자공학과',200,'3호관');
insert into tbl_level ( deptno, dname, college, loc ) values ( 202,'기계공학과',200,'4호관');
<계층 구조 확인>
SELECT LPAD(' ', (LEVEL-1)*3) || dname 조직도
, deptno, college, LEVEL
FROM tbl_level
START WITH deptno = 10 -- deptno IS NULL
CONNECT BY PRIOR deptno = college;

5) 계층구조에서 가지 제거 방법
<정보미디어학부 가지를 삭제>
SELECT LPAD(' ', (LEVEL-1)*3) || dname 조직도
, deptno, college, LEVEL
FROM tbl_level
WHERE dname != '정보미디어학부'
START WITH deptno = 10 -- deptno IS NULL
CONNECT BY PRIOR deptno = college;

> 위의 쿼리를 실행시켜보면 정보미디어학부는 없어지지만 정보미디어학부의 하위 가지는 그대로 남아있다. 아래 쿼리를 실행시켜보면 정비미디어학부와 하위 가지 조회되지 않는 것을 확인할 수 있다.
<정보미디어학부 + 하위(자식) 가지도 삭제>
SELECT LPAD(' ', (LEVEL-1)*3) || dname 조직도
, deptno, college, LEVEL
FROM tbl_level
START WITH deptno = 10 -- deptno IS NULL
CONNECT BY PRIOR deptno = college AND dname != '정보미디어학부';

3. MERGE(병합, 통합)
(1) 구조가 같은 두 개의 테이블을 비교하여 하나의 테이블로 합치기 위한 데이터 조작이다.
(2) UNION, UNION ALL 과의 차이점?
UNION과 UNION ALL은 A U B 이지만 병합은 A <- B 즉, 하나의 테이블로 합쳐지는 것
(3) 사용하는 곳?
하루에 수만건씩 발생하는 데이터를 하나의 테이블에 관리할 경우 대량의 데이터로 인해 질의문의 성능이 저하된다. 이런 경우, 지점별로 별도의 테이블에서 관리하다가 년말에 종합 분석을 위해 하나의 테이블로 합칠 때 merge 문을 사용하면 편리하다.
(4) merge하고자 하는 소스 테이블의 행을 읽어 타깃 테이블에 매치되는 행이 존재하면 새로운 값으로 UPDATE를 수행하고, 만일 매치되는 행이 없을 경우 새로운 행을 타킷 테이블에서 INSERT를 수행한다.

(5) merge 문에서 where 절 대신 on이 사용된다. 또한 when matched then 절과 when not matched then 절에는 테이블명 대신 alias(별칭)를 사용한다.
(6)
【형식】
MERGE [hint] INTO [schema.] {table ¦ view} [t_alias]
USING {{[schema.] {table ¦ view}} ¦
subquery} [t_alias]
ON (condition-조건) [merge_update_clause-병합조건] [merge_insert_clause]
[error_logging_clause];
【merge_update_clause 형식】
WHEN MATCHED THEN UPDATE SET {column = {expr ¦ DEFAULT},...}
[where_clause] [DELETE where_clause]
【merge_insert_clause 형식】
WHEN NOT MATCHED THEN INSERT [(column,...)]
VALUES ({expr,... ¦ DEFAULT}) [where_clause]
【where_clause 형식】
WHERE condition
【error_logging_clause 형식】
LOG ERROR [INTO [schema.] table] [(simple_expression)]
[REJECT LIMIT {integer ¦ UNLIMITED}]
(7) 테스트
MERGE를 테스트 하기 위해서 아래와 같은 2개의 테이블 생성 및 데이터 추가를 해보자
<테이블 생성>
CREATE TABLE tbl_emp(
id NUMBER PRIMARY KEY
, name VARCHAR2(10) NOT NULL
, salary NUMBER
, bonus NUMBER DEFAULT 100
);
<데이터 추가>
INSERT INTO tbl_emp(id, name, salary) VALUES(1001, 'jijoe', 150);
INSERT INTO tbl_emp(id, name, salary) VALUES(1002, 'cho', 130);
INSERT INTO tbl_emp(id, name, salary) VALUES(1003, 'kim', 140);
COMMIT;
<테이블 생성>
CREATE TABLE tbl_bonus(
id NUMBER
, bonus NUMBER DEFAULT 100
);
<데이터 추가>
INSERT INTO tbl_bonus(id) (SELECT id FROM tbl_emp);
COMMIT;
테이블 생성 및 데이터를 추가하고 조회해보면 아래와 같이 결과가 나온다.

이제 tbl_emp 테이블의 bonus를 tbl_bonus 테이블의 bonus 컬럼에 병합하는 쿼리를 작성한 후 실행을 시켜보겠다. (tbl_emp -> tbl_bonus)
MERGE INTO tbl_bonus b
USING (SELECT id, salary FROM tbl_emp) e
ON(b.id = e.id)
WHEN MATCHED THEN -- UPDATE
UPDATE SET b.bonus = b.bonus + e.salary * 0.01
WHEN NOT MATCHED THEN -- INSERT
INSERT (b.id, b.bonus) VALUES (e.id, e.salary * 0.01);
-- 3개 행 이(가) 병합되었습니다.
병합 후 테이블을 조회해보면 아래와 같이 변경된 것을 확인할 수 있다.

또 다른 MERGE 예시)
CREATE TABLE tbl_merge1
(
id number primary key
, name varchar2(20)
, pay number
, sudang number
);
CREATE TABLE tbl_merge2
(
id number primary key
, sudang number
);
INSERT INTO tbl_merge1 (id, name, pay, sudang) VALUES (1, 'a', 100, 10);
INSERT INTO tbl_merge1 (id, name, pay, sudang) VALUES (2, 'b', 150, 20);
INSERT INTO tbl_merge1 (id, name, pay, sudang) VALUES (3, 'c', 130, 0);
COMMIT;
INSERT INTO tbl_merge2 (id, sudang) VALUES (2,5);
INSERT INTO tbl_merge2 (id, sudang) VALUES (3,10);
INSERT INTO tbl_merge2 (id, sudang) VALUES (4,20);
COMMIT;
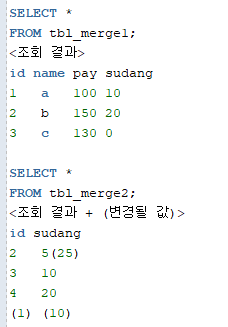
<merge1 -> merge2 병합>
MERGE INTO tbl_merge2 m2
USING(SELECT id, sudang FROM tbl_merge1) m1
ON(m2.id = m1.id)
WHEN MATCHED THEN
UPDATE SET m2.sudang = m2.sudang + m1.sudang
WHEN NOT MATCHED THEN
INSERT (m2.id, m2.sudang) VALUES (m1.id, m1.sudang);
-- 3개 행 이(가) 병합되었습니다.

4. Constraints(제약조건)
1) 테이블에 제약 조건 확인 : user_constraints 뷰(view);
* 뷰(view)는 아직 배우지 않아서 디테일한 설명은 view를 배운 후에 다시 다루도록 하겠다.
SELECT *
FROM user_constraints
WHERE table_name = 'EMP';
2) 제약조건이란?
ㄱ. data integrity(데이터 무결성)을 위해서 테이블에 레코드(행)를 추가, 수정, 삭제할 때 적용되는 규칙
ㄴ. 테이블에 의해 참조되고 있는 경우 테이블의 삭제 방지를 위해서도 사용된다.
DEPT(deptno PK) <-> EMP (deptno FK)
DELETE FROM dept
WHERE deptno = 30;
> ORA-02292: integrity constraint (SCOTT.FK_DEPTNO) violated - child record found
> 원인 : 자식테이블(emp)의 deptno가 부모테이블(dept)의 deptno를 참조하고 있는데 삭제하면 안된다.
ㄷ. 제약조건을 사용하는 이유?
- DML에 의해 데이터가 잘못 조작되는 것을 방지하기 위해서!
- 제약조건 없이도 기본 구조의 테이블은 생성된다. 그러나 테이블을 생성한 경우에 DML에 의한 데이터 조작이 사용자가 원하는 대로 되지 않을 수 있다.
예) 주민등록번호
도메인 무결성 위배 -> 제약조건 설정
rrn char(14) INSERT INTO 테이블명 (rrn) VALUES('123') -> 123 값이 들어가짐
중복되는 주민등록번호 들어감
3) 데이터의 무결성이란?
- 데이터가 허가되지 않는 값으로 추가, 수정, 삭제할 수 없도록 제한하는 특성
(1) 개체 무결성(Entity Integrity)
- 릴레이션(테이블)에 저장되는 튜플(tuple = row = record)의 유일성을 보장하기 위한 제약조건이다 == PK 고유키
INSERT INTO dept VALUES(10, 'QC', 'SEOUL');
> ORA-00001: unique constraint (SCOTT.PK_DEPT) violated
> 원인 : deptno = 10 존재하기 때문에 10번으로 부서를 추가할 수 없다. -> 개체 무결성
(2) 참조 무결성(Relational Integrity)
- 릴레이션(테이블) 간의 데이터의 일관성을 보장하기 위한 제약조건이다.
-> deptno 테이블 : 10, 20, 30, 40
-> emp 테이블 : 90번 사원이 존재하면 X(deptno 테이블에 90번 부서는 없기 때문에)
UPDATE emp
SET deptno = 90
WHERE empno = 7369;
> ORA-02291: integrity constraint (SCOTT.FK_DEPTNO) violated - parent key not found
> emp 테이블의 deptno는 dept 테이블의 deptno 참조하고 있고, deptno에는 90번 부서가 없기 때문에 참조할 수 X
(3) 도메인 무결성(Domain integrity)
- 컬럼(속성)에서 허용 가능한 값의 범위를 지정하기 위한 제약조건이다.
- 컬럼(속성)의 데이터 타입, 길이, 기본 키, 유일성, null 허용, 허용 값의 범위와 같은 다양한 제약조건을 지정할 수 있다.
예) 국어 점수 - kor NUMBER(3) NOT NULL DEFAULT 0
> 입력을 하지 않으면 기본값 0으로 입력( DEFAULT 0 )
> 필수 입력사항( NOT NULL )
> -999 ~ 999 정수를 저장할 수 있다. 0 <= 정수 <= 100 (범위제한)
4) 제약 조건을 선언(설정)하는 방법
(1) CREATE TABLE 테이블 생성할 때
(2) ALTER TABLE 테이블 수정할 때 -> 기존 테이블에 무결성 제약조건 추가하는 방법
* view 배울 때 view 관련된 부분은 다시 다루도록 하겠다.
CREATE TABLE 테이블명(
id 자료형 PRIMARY KEY <-- 제약조건 설정
cnt DEFAULT 0 <-- 제약조건 설정
tel NOT NULL <-- 제약조건 설정
);
ALTER TABLE 테이블명
ADD [CONSTRAINT 제약조건명] 제약조건타입 (컬럼명);
5) 제약 조건의 종류 5가지
(1) PRIMARY KEY 제약조건(고유키 PK)
(2) FOREIGN KEY 제약조건(외래키, 참조키 FK)
(3) NOT NULL 제약조건(NN)
(4) UNIQUE KEY 제약조건(유일성 UK)
(5) CHECK 제약조건(CK)
6) 제약조건을 생성하는 2가지 방법
(1) 컬럼 레벨(column level) == IN-LINE constaint 방법
- 컬럼 뒤에 제약조건을 붙이는 방식으로 복합키 설정은 할 수 없다.
(2) 테이블 레벨(table level) == OUT-LINE constaint 방법
- 테이블 선언을 다 한 후에 마지막에 제약조건 설정하는 방식으로 NOT NULL 제약조건 테이블레벨 방식으로 지정 X, 컬럼명 있는 부분에 같이 넣어줘야함 / 복합키 설정 O
* CONSTRAINTS [제약조건명] PRIMARY KEY(컬럼명 [,컬럼명, 컬럼명...] )
컬럼명이 여러 개 들어와서 PK를 여러 개 주는 것을 복합키라고 한다.
생성 및 테스트)
ㄱ. 제약조건 X 테이블
CREATE TABLE tbl_constraint(
empno NUMBER(4) NOT NULL
, ename VARCHAR2(20) NOT NULL
, deptno NUMBER(2) NOT NULL
, kor NUMBER(3)
, email VARCHAR(50)
, city VARCHAR(20)
);
-- Table TBL_CONSTRAINT이(가) 생성되었습니다.
INSERT INTO tbl_constraint (empno, ename, deptno, kor, email, city)
VALUES(null, null, null, null, null, null);
> NOT NULL 제약조건 지정 후 에러 발생
> ORA-01400: cannot insert NULL into ("SCOTT"."TBL_CONSTRAINT"."EMPNO")
> 필수 입력 컬럼 지정 : NOT NULL 제약조건
INSERT INTO tbl_constraint (empno, ename, deptno, kor, email, city)
VALUES(1111, null, null, null, null, null);
> NOT NULL 제약조건 지정 후 에러 발생
> ORA-01400: cannot insert NULL into ("SCOTT"."TBL_CONSTRAINT"."EMPNO")
INSERT INTO tbl_constraint (empno, ename, deptno, kor, email, city) VALUES(1111, 'admin', 10, null, null, null);
INSERT INTO tbl_constraint (empno, ename, deptno, kor, email, city) VALUES(1111, 'hong', 10, null, null, null);
> 같은 사원 번호로 2명이 등록 -> 개체 무결성 위배
ㄴ. 컬럼 레벨(column level) 방식으로 제약조건 설정
CREATE TABLE tbl_column_level(
empno NUMBER(4) NOT NULL CONSTRAINTS pk_tblcolumnlevel_empno PRIMARY KEY
, ename VARCHAR2(20) NOT NULL
- dept 테이블의 PK(deptno) 컬럼을 참조하는 외래키(=참조키) FK 설정
, deptno NUMBER(2) NOT NULL CONSTRAINTS fk_tblcolumnlevel_deptno REFERENCES dept(deptno)
- kor은 0 ~ 100점만 넣을 수 있도록 설정 CHECK(CK)
, kor NUMBER(3) CONSTRAINTS ck_tblcolumnlevel_kor CHECK (kor BETWEEN 0 AND 100)
, email VARCHAR(50) CONSTRAINTS uk_tblcolumnlevel_email UNIQUE -- 유일성(UK)
- 서울, 부산, 대구, 대전만 입력 가능
, city VARCHAR(20) CONSTRAINTS ck_tblcolumnlevel_city CHECK (city IN ('서울', '부산', '대구', '대전') )
);
-- Table TBL_COLUMN_LEVEL이(가) 생성되었습니다.
ㄷ. 테이블 레벨(table level) 방식으로 제약조건 설정
CREATE TABLE tbl_table_level(
empno NUMBER(4) NOT NULL
, ename VARCHAR2(20) NOT NULL
, deptno NUMBER(2) NOT NULL
, kor NUMBER(3)
, email VARCHAR(50)
, city VARCHAR(20)
, CONSTRAINTS pk_tbltablelevel_empno PRIMARY KEY(empno)
, CONSTRAINTS fk_tbltablelevel_deptno FOREIGN KEY(deptno) REFERENCES dept(deptno)
, CONSTRAINTS uk_tbltablelevel_email UNIQUE(email)
, CONSTRAINTS ck_tbltablelevel_kor CHECK (kor BETWEEN 0 AND 100)
, CONSTRAINTS ck_tbltablelevel_city CHECK (city IN ('서울', '부산', '대구', '대전') )
);
-- Table TBL_TABLE_LEVEL이(가) 생성되었습니다.
<제약조건확인>

<데이터 추가하면서 무결성 위배 확인해보기>
INSERT INTO tbl_table_level (empno, ename, deptno, kor, email, city)
VALUES('1111', 'admin', 20, 90, 'admin@naver.com', '서울');
> ORA-01438: value larger than specified precision allowed for this column
> 사원번호 4자리 넣어야 하는데 5자리 입력해서 발생
INSERT INTO tbl_table_level (empno, ename, deptno, kor, email, city)
VALUES('1111', 'hong', 50, 150, 'hong@naver.com', '포항');
> 개체 무결성 위배
> ORA-00001: unique constraint (SCOTT.PK_TBLTABLELEVEL_EMPNO) violated
> 사원번호는 PK이므로 에러 발생(중복 발생 X)
> 참조 무결성 위배
> ORA-02291: integrity constraint (SCOTT.FK_TBLTABLELEVEL_DEPTNO) violated - parent key not found
> dept 테이블에는 deptno 50번이 없기 때문에 에러 발생
> 도메인 무결성 위배
> ORA-02290: check constraint (SCOTT.CK_TBLTABLELEVEL_KOR) violated
> kor에 입력할 수 있는 값은 0 ~ 100 정수이기 때문에 에러 발생
> ORA-02290: check constraint (SCOTT.CK_TBLTABLELEVEL_CITY) violated
> city는 서울, 대전, 대구, 부산만 입력할 수 있기 때문에 에러 발생
INSERT INTO tbl_table_level (empno, ename, deptno, kor, email, city)
VALUES('3333', 'choi', 30, null, null, null);
> ORA-01400: cannot insert NULL into ("SCOTT"."TBL_TABLE_LEVEL"."ENAME")
> ename은 NOT NULL 제약조건이기 때문에 반드시 값을 줘야한다.
7) 테이블에서 제약 조건을 제거
• 제약조건은 수정할 수 없으며, 기존의 constraint를 삭제 후 재생성하여야 한다.
• constraint를 삭제할려면, 직접 constraint명을 사용해서 삭제하거나 또는 constraint가 포함된 테이블을 삭제하면 그 테이블에 속한 constraint도 함께 삭제된다.
• 무결성 constraint를 삭제할 때, 그 constraint는 더 이상 서버에 의해서 적용되지 않기 때문에 data dictionary에서 확인할 수 없다.
• primary key는 테이블당 하나만 존재하므로 삭제시 constraint명을 지정하지 않아도 primary key 제약조건이 삭제된다.
[제거하는 형식]
ALTER TABLE 테이블명
DROP [CONSTRAINT constraint명 | PRIMARY KEY | UNIQUE(컬럼명)]
[CASCADE];
제거 예시)
(1) tbl_table_level 테이블에서 PK 제거
ALTER TABLE tbl_table_level
DROP PRIMARY KEY;
- 제약조건명으로 삭제하는 방법
ALTER TABLE tbl_table_level
DROP CONSTRAINT pk_tbltablelevel_empno;
(2) PK를 기존 테이블에 추가
ALTER TABLE tbl_table_level
ADD CONSTRAINT pk_tbltablelevel_empno PRIMARY KEY (empno);
문제1) tbl_table_level 테이블에서 제약 조건을 확인하고, 모든 CK 제약조건만 삭제
SELECT *
FROM user_constraints
WHERE table_name = UPPER('tbl_table_level');
ALTER TABLE tbl_table_level
DROP CONSTRAINTS CK_TBLTABLELEVEL_KOR;
ALTER TABLE tbl_table_level
DROP CONSTRAINTS CK_TBLTABLELEVEL_CITY;
--
문제2) kor 컬럼에 NN 제약조건 추가하기
방법 2가지)
ALTER TABLE 테이블명
ADD CONSTRAINT 제약조건명 CHECK( kor IS NOT NULL );
또는
ALTER TABLE tbl_table_level
MODIFY kor NOT NULL;
8) 제약조건 활성화/비활성화
- 제약조건을 설정해놨는데 잠시 사용하지 않는 것
ALTER TABLE 테이블명
ENABLE CONSTRAINT 제약조건명 [CASCADE];
ALTER TABLE 테이블명
DISABLE CONSTRAINT 제약조건명 [CASCADE];
9) FOREIGN KEY(FK) 설정시 두 가지 옵션 설명
(1) ON DELETE CASCADE 옵션
- 부모 테이블의 행이 삭제될 때 이를 참조한 자식 테이블의 행을 동시에 삭제할 수 있다.
(2) ON DELETE SET NULL 옵션
- 자식 테이블이 참조하는 부모 테이블의 값이 삭제되면 자식 테이블의 값을 NULL 값으로 변경시킨다.
【컬럼레벨의 형식】
컬럼명 데이터타입 CONSTRAINT constraint명
REFERENCES 참조테이블명 (참조컬럼명)
[ON DELETE CASCADE | ON DELETE SET NULL]
【테이블레벨의 형식】
컬럼명 데이터타입,
컬럼명 데이터타입,
...
CONSTRAINT constraint명 FOREIGN KEY(컬럼)
REFERENCES 참조테이블명 (참조컬럼명)
[ON DELETE CASCADE | ON DELETE SET NULL]
테스트)
1) emp -> tbl_emp 테이블 생성
기존 테이블이 있다면 삭제 후 진행
DROP TABLE tbl_emp;
CREATE TABLE tbl_emp AS( SELECT * FROM emp);
dept -> tbl_dept 테이블 생성
CREATE TABLE tbl_dept AS( SELECT * FROM dept);
2) tbl_emp와 tbl_dept 테이블의 제약 조건 확인
SELECT *
FROM user_constraints
WHERE table_name IN( 'TBL_EMP', 'TBL_DEPT');
3) tbl_emp(empno), tbl_dept(deptno) 제약조건 PK 추가
ALTER TABLE tbl_emp
ADD CONSTRAINT pk_tblemp_empno PRIMARY KEY (empno);
ALTER TABLE tbl_dept
ADD CONSTRAINT pk_tbldept_deptno PRIMARY KEY (deptno);
4) tbl_dept(deptno PK) -> tbl_emp(deptno) 참조키 FK 설정
ALTER TABLE tbl_emp
ADD CONSTRAINTS fk_tblemp_deptno FOREIGN KEY(deptno) REFERENCES tbl_dept(deptno);
5) 조회
SELECT * FROM tbl_emp;
SELECT * FROM tbl_dept;
6) tbl_dept 테이블에서 30번 부서를 삭제하면 tbl_emp 테이블에 30번 부서원들도 삭제하고싶다.
-> ON DELETE CASCADE 옵션
DELETE FROM tbl_dept
WHERE deptno = 30;
> ORA-02292: integrity constraint (SCOTT.FK_TBLEMP_DEPTNO) violated - child record found
> 자식 레코드가 참조하고 있기 때문에 삭제할 수 없다.
- 6) 에서 원하는 데이터를 삭제하기 위한 작업 7) ~ 9)
7) fk_tblemp_deptno 제약조건 삭제
ALTER TABLE tbl_emp
DROP CONSTRAINTS fk_tblemp_deptno;
8) FK 제약조건 다시 추가하기 + ON DELETE CASCADE 옵션 추가
ALTER TABLE tbl_emp
ADD CONSTRAINTS fk_tblemp_deptno FOREIGN KEY(deptno) REFERENCES tbl_dept(deptno) ON DELETE CASCADE;
8-2) FK 제약조건 다시 추가하기 + ON DELETE SET NULL 추가
ALTER TABLE tbl_emp
ADD CONSTRAINTS fk_tblemp_deptno FOREIGN KEY(deptno) REFERENCES tbl_dept(deptno) ON DELETE SET NULL;
9) tbl_dept 테이블에서 30번 부서를 삭제하면 tbl_emp 테이블에 30번 부서원들도 삭제되어짐
DELETE FROM tbl_dept
WHERE deptno = 30;
SELECT * FROM tbl_emp;
SELECT * FROM tbl_dept;
[참고사항] FOREIGN KEY 생성시 주의사항
• 참조하고자 하는 부모 테이블을 먼저 생성해야 한다.
• 참조하고자 하는 컬럼이 PRIMARY KEY 또는 UNIQUE 제약조건이 있어야 한다.
• 테이블 사이에 PRIMARY KEY와 FOREIGN KEY가 정의 되어 있으면, primary key 삭제시 foreign key 컬럼에 그 값이 입력되어 있으면 삭제가 안된다. (단, FK 선언때 ON DELETE CASCADE나 ON DELETE SET NULL옵션을 사용한 경우에는 삭제된다.)
• 부모 테이블을 삭제하기 위해서는 자식 테이블을 먼저 삭제해야 한다.
ps. JOIN도 일부분 배우긴 했지만 다 배우지는 않아서 내일 TIL에 정리할 예정이다!
'TIL > Oracle' 카테고리의 다른 글
| [SIST] Oracle_days13_DB모델링 (0) | 2022.04.20 |
|---|---|
| [SIST] Oracle_days12_JOIN 관련 (0) | 2022.04.19 |
| [SIST] Oracle_days10 (0) | 2022.04.15 |
| [SIST] Oracle_days09 (0) | 2022.04.14 |
| [SIST] Oracle_days08 (0) | 2022.04.13 |