오늘도 여러 개의 문제를 풀고 중간 중간 새로운 개념을 배우거나 문제를 다 풀고 다른 문제에 새로운 개념을 적용하는 식으로 수업을 했다.
문제 중에 새로운 개념이 포함되거나 조금 어렵다고 느껴진 문제들을 정리하고 새로운 개념을 정리하려고한다!
1. [문제]
문제1) emp 에서 평균PAY 보다 같거나 큰 사원들만의 급여 합을 출력.
풀이1)

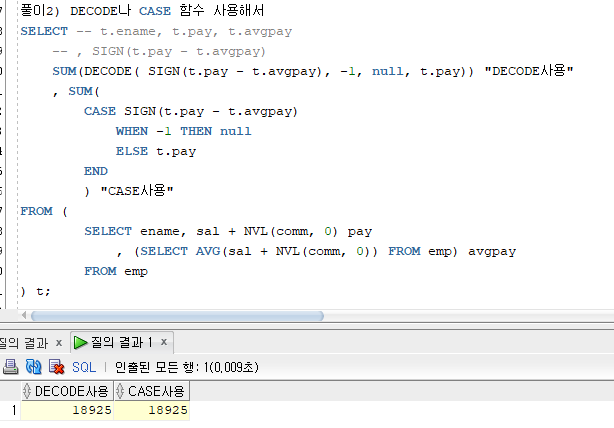
풀이2)
문제2) emp 테이블의 ename, pay, 최대pay값(5000)을 100%로 계산해서 각 사원의 pay를 백분률로 계산해서 10% 당 별하나(*)로 처리해서 출력 ( 소숫점 첫 째 자리에서 반올림해서 출력 )

문제3) insa 테이블에서 '2022.10.10'을 기준으로 아래와 같이 출력하는 쿼리 작성.

풀이1) CASE 사용

풀이2) DECODE 사용

문제4) insa테이블에서 '2022.10.10'기준으로 이 날이 생일인 사원수,지난 사원수, 안 지난 사원수를 출력하는 쿼리 작성
풀이1)

풀이2)

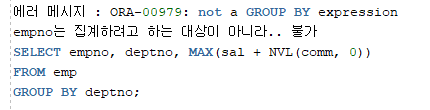
문제5) emp 테이블에서 각 부서별 급여를 가장 많이 받는 사원의 pay를 출력 - GROUP BY 사용

아래 empno 컬럼을 추가하면 에러가 발생한다.
그 이유는 deptno은 GROUP BY절로 그룹화를 하였고 sal + NLV(comm, 0)은 MAX로 그룹화를 하였는데 empno는 그룹화를 하지 않았기 때문이다.
2. [JOIN 맛보기]
- [형식]
FROM A JOIN B ON 조인조건;
- 조인조건 : A와 B테이블의 관계
ex) emp와 dept 테이블은 각각 테이블의 deptno 컬럼으로 참조(관계)되고 있다.

문제1) emp, salgrade 두 테이블을 참조해서 아래 결과 출력 쿼리 작성

3. 상관 서브 쿼리(Correlated) ***
(1) 메인쿼리의 값(e.deptno)을 서브쿼리에서 사용한 후 그 결과값을 다시 메인쿼리에서 사용
즉, 메인쿼리의 값을 서브쿼리에 주고 서브쿼리에서 사용하여 나온 결과를 다시 메인쿼리에서 사용하는 것
(2) correlated subquery는 한개의 행을 비교할 때마다 결과가 main으로 리턴된다.
(3) 내부적으로 성능이 저하된다.
(4) 메인쿼리와 서브쿼리간에 결과를 교환하기 위하여 서브쿼리의 WHERE 조건절에서 메인쿼리의 테이블과 연결한다.
예시)

예시의 서브쿼리만 실행하면 에러가 발생한다.
> SELECT MAX(sal + NVL(comm, 0)) FROM emp WHERE deptno = e.deptno
> 에러메시지 : ORA-00904: "E"."DEPTNO": invalid identifier
> 해석 : e.deptno를 찾을 수 없음. 밖에 메인쿼리에 있기 때문에
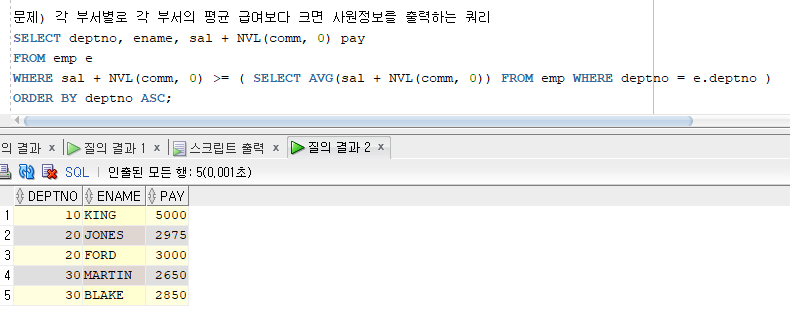
문제1) 각 부서별로 각 부서의 평균 급여보다 크면 사원정보를 출력하는 쿼리
문제2) insa 테이블에서 만나이와 세는나이 출력하기
만나이는 올해년도 - 생일년도 생일이지남여부에 따라 생일이 지나지않으면 -1
세는나이 올해년도 - 생일년도 + 1

4. TOP-N 방식(분석)
(1) 최대값이나 최소값을 가진 컬럼을 질의할 때 유용하게 사용되는 분석방법이다.
(2) inline view에서 ORDER BY 절을 사용할 수 있으므로 데이터를 원하는 순서로 정렬도 가능하다.
(3) ROWNUM 컬럼은 subquery에서 반환되는 각 행에 순차적인 번호를 부여하는 pseudo(수도, 의사=가짜) 컬럼이다. 즉, pseudo는 순번을 자동으로 부여해주는 가짜 컬럼이다.
(4) n값은 < 또는 >=를 사용하여 정의하며, 반환될 행의 개수를 지정한다.
【형식】
SELECT 컬럼명,..., ROWNUM
FROM (SELECT 컬럼명,... from 테이블명
ORDER BY top_n_컬럼명)
WHERE ROWNUM <= n;
문제1) emp 테이블에서 pay를 많이 받는 3명 출력

주의!! WHERE 절에서 BETWEEN으로 가져오려고하면 가져올 수 없다.
에러는 발생하지 않지만 결과값이 아무것도 나오지 않는다. TOP-N 방식은 처음부터 가져와야 한다.
5. 순위 매기는 함수
순위 매기는 함수에는 아래 3가지가 있다.
1) DENSE_RANK() 함수
(1) 그룹 내에서 차례로 된 행의 rank를 계산하여 NUMBER 데이터타입으로 순위를 반환한다.
(2) 해당 값에 대한 우선순위를 결정(중복 순위 계산 안함) ex) 9등 9등 10등
【Aggregate 형식】
DENSE_RANK ( expr[,expr,...] ) WITHIN GROUP
(ORDER BY expr [[DESC ? ASC] [NULLS {FIRST ? LAST} , expr,...] )
【Analytic 형식】
DENSE_RANK ( ) OVER ([query_partion_clause] order_by_clause )
2) RANK() 함수
(1) 그룹 내에서 차례로 된 행의 rank를 계산하여 NUMBER 데이터타입으로 순위를 반환한다.
(2) 해당 값에 대한 우선순위를 결정(중복 순위 계산 함) ex) 9등 9등 11등
【Aggregate 형식】
RANK(expr[,...]) WITHIN GROUP (ORDER BY {expr [DESC ¦ ASC] [NULLS {FIRST ¦ LAST}] } )
【Analytic 형식】
RANK() OVER( [query_partition_clause] order_by_clause )
3) ROW_NUMBER() 함수
(1) 분할별로 정렬된 결과에 대해 순위를 부여하는 기능을 가지고 있는 함수
(2) 분할은 전체 행을 특정 컬럼을 기준으로 분리하는 기능으로 GROUP BY 절에서 그룹화하는 방법과 같은 개념이다.
【형식】
ROW_NUMBER () OVER ([query_partition_clause] order_by_clause )
예제1) emp 테이블에서 pay를 많이 받는 3명 출력

예제2) emp 테이블에서 각 부서별로 급여(pay)를 가장 많이 받는 사원 1명 출력
> 여기서 사용한 PARTITION BY는 해당 컬럼으로 파티션을 나눈뒤 순위를 매긴다는 뜻이다.

예제3) emp에서 pay가 상위 20%에 드는 사원 정보를 조회

위의 예제3 문제를 PERCENT_RANK() 함수를 사용하여 풀 수 있다.
6. PERCENT_RANK() 함수
이 함수는 맛보기 정도로만 다뤘기 때문에 문제를 통해서만 살펴본 것으로 정리하겠다.
수업 때 자세히 배우게 되면 그 때 다시 정리할 예정이다!
【aggregate 형식】
PERCENT_RANK(expr,...) WITHIN GROUP (ORDER BY expr { [DESC ¦ ASC] [NULLS {FIRST ¦ LAST}] },...)
【Analytic 형식】
PERCENT_RANK() OVER ( [query_partition_clause] order_by_clause )
아래 쿼리와 결과물을 살펴보면 PERCENT_RANK() 함수를 통해 % 비율로 나타나는 것을 알 수 있다.
상위 20%를 구하기 위해서 WHERE 절에 조건을 주면되는데 여기서 정확히 상위 20%의 값이 나오지는 않는다고 한다. 이 부분은 개념을 정확히 알고난 뒤에 다시 정리를 하겠다.

WHERE 절에 조건을 주면 아래와 같이 나타난다.

'TIL > Oracle' 카테고리의 다른 글
| [SIST] Oracle_days09 (0) | 2022.04.14 |
|---|---|
| [SIST] Oracle_days08 (0) | 2022.04.13 |
| [SIST] Oracle_days06 (0) | 2022.04.11 |
| [SIST] Oracle_days05 (0) | 2022.04.08 |
| [SIST] Oracle_days04 (0) | 2022.04.07 |