[SIST] Oracle_days09
1. 복습 문제
문제1) emp 테이블의 각 JOB별 사원수 조회하기
SELECT *
FROM (SELECT job FROM emp)
PIVOT( COUNT(*) FOR job in('CLERK', 'SALESMAN', 'PRESIDENT', 'MANAGER', 'ANALYST' ) );

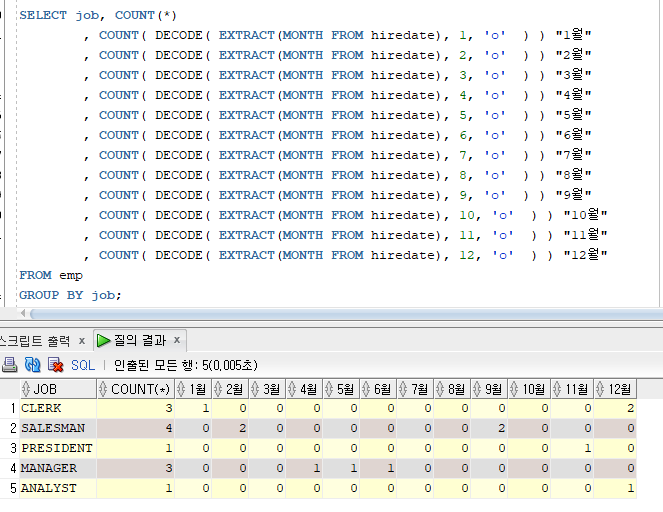
문제2) emp 테이블에서 [JOB별로] 각 월별 입사한 사원의 수를 조회
방법1) COUNT, DECODE 사용
SELECT job, COUNT(*)
, COUNT( DECODE( EXTRACT(MONTH FROM hiredate), 1, 'o' ) ) "1월"
, COUNT( DECODE( EXTRACT(MONTH FROM hiredate), 2, 'o' ) ) "2월"
, COUNT( DECODE( EXTRACT(MONTH FROM hiredate), 3, 'o' ) ) "3월"
, COUNT( DECODE( EXTRACT(MONTH FROM hiredate), 4, 'o' ) ) "4월"
, COUNT( DECODE( EXTRACT(MONTH FROM hiredate), 5, 'o' ) ) "5월"
, COUNT( DECODE( EXTRACT(MONTH FROM hiredate), 6, 'o' ) ) "6월"
, COUNT( DECODE( EXTRACT(MONTH FROM hiredate), 7, 'o' ) ) "7월"
, COUNT( DECODE( EXTRACT(MONTH FROM hiredate), 8, 'o' ) ) "8월"
, COUNT( DECODE( EXTRACT(MONTH FROM hiredate), 9, 'o' ) ) "9월"
, COUNT( DECODE( EXTRACT(MONTH FROM hiredate), 10, 'o' ) ) "10월"
, COUNT( DECODE( EXTRACT(MONTH FROM hiredate), 11, 'o' ) ) "11월"
, COUNT( DECODE( EXTRACT(MONTH FROM hiredate), 12, 'o' ) ) "12월"
FROM emp
GROUP BY job;
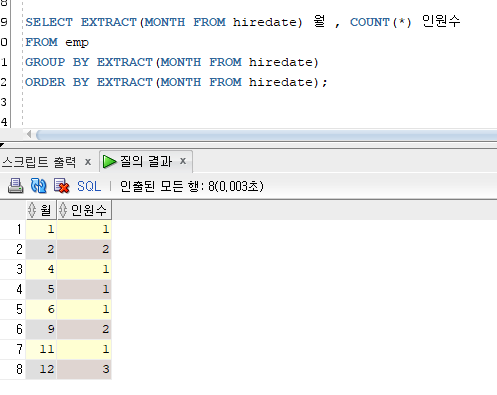
방법2) GROUP BY 절 사용
SELECT EXTRACT(MONTH FROM hiredate) 월 , COUNT(*) 인원수
FROM emp
GROUP BY EXTRACT(MONTH FROM hiredate)
ORDER BY EXTRACT(MONTH FROM hiredate);

방법3) PIVOT 사용
SELECT *
FROM(SELECT job, EXTRACT(MONTH FROM hiredate) 월 FROM emp)
PIVOT(COUNT(*) FOR 월 IN ( 1,2,3,4,5,6,7,8,9,10,11,12));
문제3) emp 테이블에서 각 부서별 급여 많이 받는 사원 2명씩 출력
SELECT *
FROM(
SELECT RANK() OVER(PARTITION BY deptno ORDER BY sal DESC) seq, emp.*
FROM emp
) t
WHERE seq <= 2;

2. PIVOT 함수 사용하는 문제
문제1) emp 테이블에서 grade 등급별 사원수 조회
PIVOT 풀이)
SELECT *
FROM(SELECT deptno, grade FROM emp, salgrade WHERE sal BETWEEN losal AND hisal )
PIVOT( COUNT(*) FOR grade IN(1, 2, 3, 4, 5));
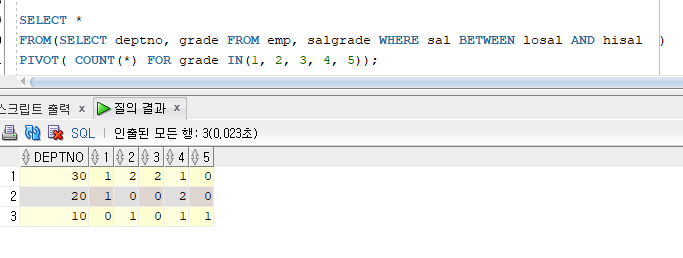
> deptno 컬럼을 추가하니 deptno 별로 등급별 사원 수를 조회할 수 있음
COUNT(), DECODE() 풀이)
SELECT COUNT(*)
, COUNT(DECODE(grade, 1, 'o')) "1등급"
, COUNT(DECODE(grade, 2, 'o')) "2등급"
, COUNT(DECODE(grade, 3, 'o')) "3등급"
, COUNT(DECODE(grade, 4, 'o')) "4등급"
, COUNT(DECODE(grade, 5, 'o')) "5등급"
FROM emp e, salgrade s
WHERE sal BETWEEN losal AND hisal;
GROUP BY 절 풀이)
SELECT grade || '등급' 등급, COUNT(*) 사원수
FROM emp e, salgrade s
WHERE sal BETWEEN losal AND hisal
GROUP BY grade
ORDER BY grade
문제2) emp 테이블에서 년도별 입사사원수를 조회
PIVOT 풀이)
SELECT *
FROM(SELECT TO_CHAR(hiredate, 'YYYY') hire_year FROM emp)
PIVOT( COUNT(*) FOR hire_year IN(1980, 1981, 1982));

COUNT(), DECODE() 풀이)
SELECT COUNT(DECODE(TO_CHAR(hiredate, 'YYYY'), 1980, 'o')) "1980"
, COUNT(DECODE(TO_CHAR(hiredate, 'YYYY'), 1981, 'o')) "1981"
, COUNT(DECODE(TO_CHAR(hiredate, 'YYYY'), 1982, 'o')) "1982"
FROM emp;
GROUP BY 풀이)
SELECT TO_CHAR(hiredate, 'YYYY') 입사년도, COUNT(*) 사원수
FROM emp
GROUP BY TO_CHAR(hiredate, 'YYYY') ;
[PIVOT 응용하기]

위의 결과처럼 나오는 것을 PIVOT을 사용해서 아래와 같은 결과로 나오게 하기

SELECT *
FROM(
SELECT
TRUNC((no-1) / 3) + 1 no
, name, jumsu
, DECODE(MOD(no, 3), 1, '국어', 2, '영어', 0, '수학') 과목
FROM tbl_pivot
)
PIVOT( SUM(jumsu) FOR 과목 IN( '국어', '영어', '수학' ) )
ORDER BY no ASC;

3. dbms_random package
- Oracle의 dbms_random 패키지(package) != 자바의 패키지 개념과 다르다.
- PL/SQL = 확장된 SQL + PL(절차적 언어)
- PL/SQL 5가지 종류 중에 하나가 package 이다.
- SELECT dbms_random. ->입력 후 아래와 같이 종류가 나온다.

위의 종류 중 value와 string에 대해서만 다뤄보도록 하겠다.
1) dbms_random.value( [n] [,m] )
- n <= values < m 실수를 돌려준다
- 기본값은 0.0 <= value < 1.0
2) dbms_random.string( 'a', n )
- 임의의 문자를 돌려준다.
value와 string 예시)


4. 오라클 자료형(Data Type)
1) 문자 자료형
(1) CHAR
ㄱ. 고정길이 문자 자료형
char(10) 선언후 'abc' 저장
10byte = ['a']['b']['c'][][][][][][][]
-> 남은 7바이트 메모리를 확보하고 있는것 | 즉, 10바이트 고정 메모리
ㄴ. 1byte ~ 2000byte 저장 가능
ㄷ. 형식
CHAR(size [BYTE|CHAR])
char(3) --> size만 줬다면.. == char(3 byte) 라고 쓰는 것과 동일
char(3 char) --> 이렇게 선언했다면 3문자를 저장하겠다.(바이트 상관없이)
char --> 이렇게 선언하면, char(1) == char(1 byte)를 준것과 동일
테스트)

(2) NCHAR == N + CHAR == U[N]ICODE CHAR
ㄱ. 유니코드(unicode) : 전세계 모든 언어의 1문자를 2 바이트로 처리하겠다.
ㄴ. 형식
NCHAR( [size] )
nchar == nchar() 1문자
nchar(5) 문자 종류 상관없이 5문자 저장
ㄷ. [고정길이] 문자열 + 최대 2000 바이트 저장
테스트)

(3) VARCHAR2 == VAR(가변길이) + CHAR
ㄱ. [가변길이] 문자 자료형, 최대 4000 바이트 저장 가능
ㄴ. 형식
VARCHAR2(size [byte|char])
시노님 ==> VARCHAR 즉, 뒤에 2를 안붙여도 사용 가능
ㄷ.
char = char(1 byte)
varchar2 = varchar2(4000 byte) 크기를 지정해 주지 않으면 최대값으로 크기가 잡힌다.
varchar2(10) = varchar2(10 byte)
varchar2(10 char) = 문자 10개 저장 가능
ㄹ. 고정길이 / 가변길이 차이점 설명
char(10) == char(10 byte)
varchar2(10) == varchar2(10 byte)
'kbs' 저장
char [k][b][s][''][''][''][''][''][''][''] 나머지는 빈문자로 다 채워져 있음
varchar2 [k][b][s] [][][][][][][] 나머지 버림
ㅁ. 어떤 경우에 고정길이/가변길이를 사용하는가?
char / nchar -> 고정길이 : 주민등록번호 14자리, 우편번호
varchar2 / nvarchar2 -> 가변길이 : 제목
(4) NVARCHAR2
ㄱ. N( 유니코드) + VAR(가변길이) + CHAR(문자열)
ㄴ. 최대 4000바이트 저장
ㄷ. 형식
NVARCHAR2( [size] )
nvarchar2 == nvarchar2(최대값)
2) 숫자 자료형
(1) LONG
- 가변길이의 문자를 저장하는 자료형 + 최대 2GB 저장 -> 쓸일 거의 X
(2) NUMBER( [p], [s] )
ㄱ. 숫자(정수, 실수)
ㄴ. p(precision) 정확 == 전체 자릿수인데 실제 값의 자리 범위 : 1 ~ 38
s(scale) 규모(정밀) == 소수점 이하 자릿수 범위 : -84 ~ 127
NUMBER(p) == NUMBER(p, 0) -- 소수점이 없다. 즉, 정수
NUMBER(p, s) -> 실수
NUMBER(3, 7)
-> 0.0000[][][] 실제 숫자 3개와 소수점 자리수는 7개 자리에 없는 것은 0으로 채운다.
ㄷ. NUMBER == NUMBER(38, 127) 자릿수 지정안해주면 최대 크기로 잡힌다.
테스트)


ㄹ. 만약 NUMBER(4,5)처럼 scale이 precision보다 크다면, 이는 첫자리에 0이 놓이게 된다.
실제 데이터 NUMBER 선언 저장되는 값
[p > s]
123.89 NUMBER 123.89
123.89 NUMBER(3) 124
123.89 NUMBER(3,2) precision을 초과
123.89 NUMBER(4,2) precision을 초과
123.89 NUMBER(5,2) 123.89
123.89 NUMBER(6,1) 123.9
123.89 NUMBER(6,-2) 100
[p < s] -- 만약 NUMBER(4,5)처럼 scale이 precision보다 크다면, 이는 첫자리에 0이 놓이게 된다.
.01234 NUMBER(4,5) .01234
.00012 NUMBER(4,5) .00012
.000127 NUMBER(4,5) .00013
.0000012 NUMBER(2,7) .0000012 -> .0000123 오류 발생 / .0000100 오류발생
.00000123 NUMBER(2,7) .0000012
1.2e-4 NUMBER(2,5) 0.00012
1.2e-5 NUMBER(2,5) 0.00001

0.000012 -> p == 2, s == 5 -> 0.00001 로 나온다.
0.000012 -> p == 1, s == 5 -> 에러 발생
p는 전체 자리수가 아니라 실제 값의 자릿수이다.
(3) FLOAT( [p] )
- FLOAT는 내부적으로 NUMBER처럼 나타냄, 숫자 자료형 -> 잘 사용 X
- 정밀도는 p는 1∼126 binary digits로, 1∼22bytes가 필요함
3) 날짜 자료형
(1) DATE
- 세기, 년, 월, 일 + 시, 분, 초를 저장하는 자료형
- 고정길이 7바이트 저장
(2) TIMESTAMP( [n] )
- n은 0 ~ 9까지 들어갈 수 있다.
- n은 초단위 다음에 이어서 나타낼 milli second의 자릿수로 기본값은 6이다
- 기본값 > TIMESTAMP == TIMESTAMP(6) -> 00.000000
- TIMESTAMP(9) -> 95/08/08 00:00:[00.000000000]
- DATE의 확장 형태로, 최대 9자리의 년,월,일,시,분,초,밀리초까지 보여줌
4) 2진 데이터 자료형
(1) RAW(size) / LONG RAW
- 2진 데이터 저장하는 자료형
- RAW의 최대값은 2000바이트로 반드시 size를 기술해야 하며, LONG RAW는 2GB까지 지원
> 이미지 파일을 테이블의 어떤 컬럼을 넣기 위해서는 010101 2진데이터로 변환해야되는데
이때 img RAW/LONG RAW를 사용
(2) BFILE == B(binary, 2진데이터) + FILE(외부 파일 형식으로 저장)
- 2GB 이상의 2진데이터를 저장하고자 한다면 BFILE 자료형을 사용한다.
- 2진데이터를 외부에 file형태로 (264 -1바이트)까지 저장
5) LOB([L]arge [O][B]ject)
- 2GB 이상의 자료를 저장할 때 사용
- 4000바이트까지는 LOB컬럼에 저장되지만, 그 이상이면 외부에 저장된다
- 종류 3가지
ㄱ. B + LOB = BLOB (2진데이터 저장)
ㄴ. C + LOB = CLOB (텍스트 데이터 저장)
ㄷ. N + C + LOB = NCLOB (유니코드형태의 텍스트 데이터 저장)
- 텍스트(LONG), 이미지, 이진데이터(LONG RAW) 저장시 2GB까지 저장
- 2GB 이상 대용량 저장시 LOB가 붙어있는 자료형 필요
5. ROWID pseudo(의사) 컬럼
- 부서의 행을 구별하는 고유한(유일한) 값(식별자)

6. COUNT / SUM / AVG 함수에서 OVER 사용하기
【COUNT 형식】
COUNT( [* ¦ DISTINCT ¦ ALL] 컬럼명) [ [OVER] (analytic 절) ]

- 순위함수와 동일하게 OVER 안에 PARTITION BY를 사용할 수 있다.
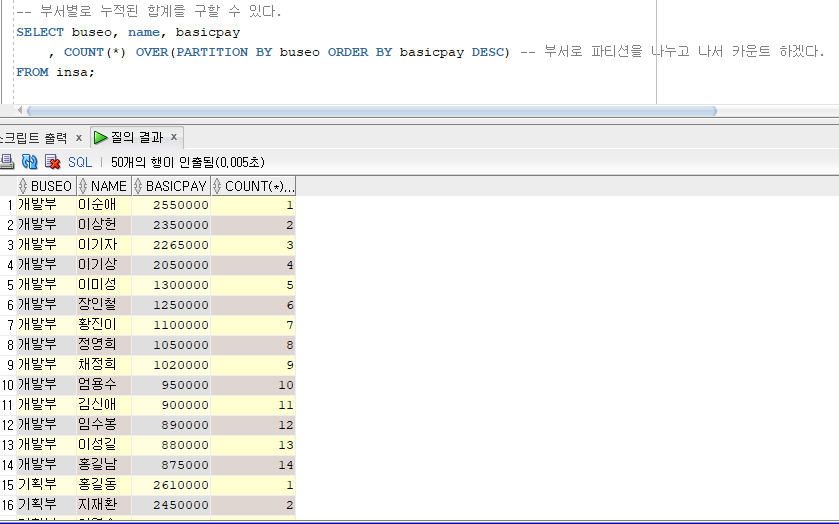
【SUM 형식】
SUM ([DISTINCT ¦ ALL] expr) [ OVER (analytic_clause) ]

개발부 이상헌 19430000
개발부 장인철 19430000
기획부 김신제 32420000 --> 개발부의 합계 + 기획부의 합계
기획부 권옥경 32420000
영업부 산마루 58044200 --> 개발부의 합계 + 기획부의 합계 + 영업부의 합계
영업부 김인수 58044200
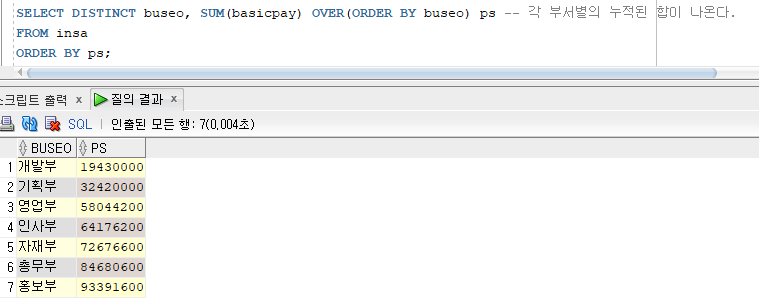
> 아래 쿼리와 같이 PARTITION BY를 주면 각 부서별의 합계를 볼 수 있다.

【AVG 형식】
AVG ( [DISTINCT ¦ ALL] expr) [ OVER (analytic_clause) ]

7. 테이블 생성, 수정, 삭제 + 데이터 추가, 수정, 삭제 등등 작업해보기
- 테이블(table) : 어떤 데이터를 저장하기 위한 장소
* DB 모델링은 다음 주에 배울 예정이다!
1) 테이블 - tbl_member 생성하기 위해 아래와 같은 컬럼을 설정할 것이다.

【간단한 테이블 생성 형식】
CREATE [GLOBAL TEMPORARY] TABLE [schema.] table명
( 열이름 데이터타입 [DEFAULT 표현식] [제약조건]
[,열이름 데이터타입 [DEFAULT 표현식] [제약조건] ]
[,...]
);
- GLOBAL TEMPORARY : 임시 테이블을 생성하겠다는 의미
임시테이블은 왜 사용할까? 로그인하고 로그아웃하기 전까지만 동안만 장바구니를 유지하고 로그아웃하면 장바구니 비우기 위해서 임시테이블 사용
- schema : 접속한 계정명
- 제약조건 : 널허용, 고유키 등등
2) 위에서 결정한 데이터 컬럼과 자료형을 가지고 테이블을 생성하는 쿼리를 작성
CREATE TABLE scott.tbl_member
(
id VARCHAR2(10) NOT NULL PRIMARY KEY
, name VARCHAR(2) NOT NULL
, age NUMBER(3)
, tel CHAR(13)
, birth DATE
, etc VARCHAR2(200)
);
--> Table SCOTT.TBL_MEMBER이(가) 생성되었습니다.
확인해보면 아래와 같이 데이터는 아무것도 없지만 빈테이블이 잘 생성이 되어져 있다.

3) 생성된 테이블 삭제해보기
DROP TABLE tbl_member;
--> Table TBL_MEMBER이(가) 삭제되었습니다.
4) 다시 테이블 생성하기(tel과 etc 컬럼 제외)
CREATE TABLE scott.tbl_member
(
id VARCHAR2(10) NOT NULL PRIMARY KEY
, name VARCHAR(2) NOT NULL
, age NUMBER(3)
, birth DATE
);
--> Table SCOTT.TBL_MEMBER이(가) 생성되었습니다.
5) 테이블 구조확인

이제 컬럼을 추가하거나 수정하거나 삭제하는 작업을 해볼 것이다.
그 전에 DDL이라는 데이터 정의어의 ALTER TABLE로 무엇을 할 수 있는지 살펴보면 아래와 같다.
(1) 새로운 컬럼 추가 ...ADD
【형식】컬럼추가
ALTER TABLE 테이블명
ADD (컬럼명 datatype [DEFAULT 값]
[,컬럼명 datatype]...);
• 한번의 add 명령으로 여러 개의 컬럼 추가가 가능하고, 하나의 컬럼만 추가하는 경우에는 괄호를 생략해도 된다.
• 추가된 컬럼은 테이블의 마지막 부분에 생성되며 사용자가 컬럼의 위치를 지정할 수 없다
• 추가된 컬럼에도 기본 값을 지정할 수 있다.
• 기존 데이터가 존재하면 추가된 컬럼 값은 NULL로 입력 되고, 새로 입력되는 데이터에 대해서만 기본 값이 적용된다.
(2) 기존 컬럼 수정
【형식】기존 컬럼 수정
ALTER TABLE 테이블명
MODIFY (컬럼명 datatype [DEFAULT 값]
[,컬럼명 datatype]...);
• 데이터의 type, size, default 값을 변경할 수 있다.
• 변경 대상 컬럼에 데이터가 없거나 null 값만 존재할 경우에는 size를 줄일 수 있다.
-> 데이터가 있는 경우 size를 줄일 수 없다! ***
• 데이터 타입의 변경은 CHAR와 VARCHAR2 상호간의 변경만 가능하다.
-> 같은 자료형 유형으로 변경 가능
• 컬럼 크기의 변경은 저장된 데이터의 크기보다 같거나 클 경우에만 가능하다.
-> 데이터가 있는 경우에는 size 증가만 가능
• NOT NULL 컬럼인 경우에는 size의 확대만 가능하다.
-> 제약조건이 NOT NULL이면 size 확대만 가능
• 컬럼의 기본값 변경은 그 이후에 삽입되는 행부터 영향을 준다.
• 컬럼이름의 [직접적인 변경]은 불가능하다.
• 컬럼이름의 변경은 서브쿼리를 통한 테이블 생성시 alias를 이용하여 변경이 가능하다.
• alter table ... modify를 이용하여 constraint(제약조건)를 수정할 수 없다.
(3) 기존 컬럼 삭제
【형식】
ALTER TABLE 테이블명
DROP COLUMN 컬럼명;
• 컬럼을 삭제하면 해당 컬럼에 저장된 데이터도 함께 삭제된다.
• 한번에 하나의 컬럼만 삭제할 수 있다.
• 삭제 후 테이블에는 적어도 하나의 컬럼은 존재해야 한다.
• DDL문으로 삭제된 컬러은 복구할 수 없다.
(4) 제약조건 추가
(5) 제약조건 삭제
제약조건에 대해서는 내일부터 배우게 되어 내일 TIL에 정리할 예정이다.
이제 컬럼을 추가, 수정, 삭제하는 작업을 해보자
6) 기존 tbl_member 테이블에 새로운 컬럼인 전화번호, 기타 컬럼 추가 - (1) 관련
ALTER TABLE tbl_member
ADD(
tel CHAR(13) NOT NULL
, etc VARCHAR2(200)
);
--> Table TBL_MEMBER이(가) 변경되었습니다.
위의 쿼리를 작성 후 실행한 다음에 테이블 구조를 살펴보면 새로 추가된 컬럼은 마지막에 들어가지는 것을 확인할 수 있다.

7) ETC 컬럼 자료형의 크기를 VARCHAR2(200) -> VARCHAR2(255) 수정하기 - (2) 관련
ALTER TABLE tbl_member
MODIFY ( etc VARCHAR2(255) );
--> Table TBL_MEMBER이(가) 변경되었습니다.
위의 쿼리를 작성 후 실행한 다음 테이블 구조를 살펴보면 size가 변경된 것을 확인할 수 있다.

8) etc 컬럼명을 bigo 컬럼명으로 수정하기
방법1) 별칭(alias) 사용
SELECT etc bigo FROM tbl_member;
방법2) 필드명을 수정
ALTER TABLE tbl_member
RENAME COLUMN etc TO bigo;
-- Table TBL_MEMBER이(가) 변경되었습니다.

9) bigo 컬럼 삭제하기
ALTER TABLE tbl_member
DROP COLUMN bigo;
--> Table TBL_MEMBER이(가) 변경되었습니다.

10) tbl_member 테이블의 이름 수정하기
RENAME tbl_member TO tbl_customer;